News
Follow @BayesDuality- [24-26 Jun, 2026] The webpage of the 4th Bayes-duality workshop is live now; register at Doorkeeper.
- [1 Oct, 2025] Summary of research results (FY 2024) available now
- [23-27 Jun, 2025] We are holding the 3rd Bayes-duality workshop in Japan.
- [17-21 Feb, 2025] Emtiyaz Khan speaking at BIRS workshop on Uncertainty Quantification in Neural Network Models [ Slides ].
- [12 Feb, 2025] New paper on Variational Learning Induces Adaptive Label Smoothing.
- [23 Jan, 2025] New paper accepted at ICLR2024 on Connecting Federated ADMM to Bayes.
- [12 Dec, 2024] New preprint on improving multitask finetuning using Bayesian model merging
- [9 Oct, 2024] The 2nd Bayes-duality workshop videos are now available!
- [1 Oct, 2024] Summary of research results (FY 2023) available now
- [12-21 Jun, 2024] We are holding the 2nd Bayes-duality workshop in Japan.
- [29 July-1 Aug, 2024] Keynote speaker at the 3rd Conference on Lifelong Learning Agents (CoLLAs) 2024
- [18-20 Mar, 2024] Invited speaker at the Deep Learning Workshop 2024
- [29 Feb, 2024] Invited speaker at the SIAM UQ 2024
- [5-7 Feb, 2024] Emtiyaz Khan will be a keynote speaker at the Bayes on the Beach 2024
- [16 Jan, 2024] Two papers accepted at ICLR 2024 on Model Merging and Conformal Prediction
- [28 Nov, 2023] Emtiyaz Khan will give an invited talk at the KAIST AI Colloquium
- [1 Nov, 2023] Emtiyaz Khan gave a keynote at IBIS, Kita-Kyushu, Japan [Slides]
- [20 Oct, 2023] Emtiyaz Khan gave an invited talk at the Continual AI Un-conference [Slides]
- [20 Oct, 2023] New preprint on Model Merging
- [23 Sep, 2023] New TMLR paper on 'Improving Continual Learning by Gradient Reconstruction'
- [23 Sep, 2023] A new Dagstuhl Seminar on the Role of Bayesianism in the Age of Modern AI is accepted (to be held Nov. 10-15, 2024)
- [22 Sep, 2023] A new NeurIPS paper on `Memory-Perturbation' is accepted.
- [21 Sep, 2023] Summary of research results (FY 2022) available now
- [12 Sep, 2023] Khan and Yoshida teams held a joint workshop to share research results
- [11 Sep, 2023] New paper on Fine prints of tempered Bayes by Pitas and Arbel accepted at ACML 2023
- [29 July, 2023] We held the first ICML workshop 2023 on "Duality principle for modern ML".
- [15-27 June, 2023] We are holding the first Bayes-duality workshop in Japan.
- [25 April, 2023] A paper on Memory-based dual-GP accepted at ICML 2023
- [17 Mar, 2023] Our workshop proposal at ICML 2023 on "Duality principle for modern ML" was accepted.
- [21 Jan, 2023] New paper on SAM as Bayes accepted at ICLR 2023 as oral (top 5% of all accepted papers)
- [21 Jan, 2023] New paper on LieGroup BLR accepted at AISTATS 2023
- [Dec 12, 2022] We organized the Continual Lifelong Learning Workshop at ACML 2022
- [Oct 5, 2022] New paper by Thomas Moellenhoff and Emtiyaz Khan on SAM as Bayes.
- [Sep, 2023] Summary of research results (FY 2021) is available
- [Dec 14, 2021] Invited talk by Emtiyaz Khan, Dharmesh Tailor, and Siddharth Swaroop at the NeurIPS Bayesian DL workshop [ Slides ]
- [Nov 1, 2021]
Research-Scientist/Post-doc/Research-Assistant positions (up to 4) at Approximate Bayesian Inference team at RIKEN-AIP, Tokyo, Japan - [Oct 1, 2021] The project launched
- [Sep 21, 2021] Funding of ≅ 2.76 Million USD approved through the JST-CREST and French ANR's Japan-French joint research calls
About the project
Goal: To develop a new learning paradigm for Artificial Intelligence (AI) that learns like humans in an adaptive, robust, and continuous fashion.
Summary: The new learning paradigm will be based on a new principle of machine learning, which we call the Bayes-Duality principle and will develop during this project. Conceptually, the new principle hinges on the fundamental idea that an AI should be capable of efficiently preserving and acquiring the relevant past knowledge, for a quick adaptation in the future. We will apply the principle to representation of the past knowledge, faithful transfer to new situations, and collection of new knowledge whenever necessary. Current Deep-learning methods lack these mechanisms and instead focus on brute-force data collection and training. Bayes-Duality aims to fix these deficiencies.
Funding and Duration:
- Funding of ≅ 2.76 Million USD approved is granted through the JST-CREST and French ANR's Japan-French joint research calls.
- The Japan side is awarded JPY 249,300,000 (≅ USD 2.23 million), and is led by Mohammad Emtiyaz Khan as the research director, and Kenichi Bannai and Rio Yokota as the two Co-PIs.
- The France side is awarded EUR 464,000 (USD 530,000) and is led by Julyan Arbel.
- The project will run for a total of 5½yrs, starting from Oct. 1, 2021 to March 31, 2026.
People
Team PIs
Approx-Bayes team

Stat-Theory team

Math-Science team


Collaborators
| Name | University | Position | Team in project |
|---|---|---|---|
| Benoît Collins | Kyoto University | Professor | Math-Science team |
| Florence Forbes | Inria Grenoble Rhône-Alpes | Principal investigator | Stat-Theory team |
| Kei Hagihara | RIKEN AIP | Postdoctoral Researcher | Math-Science team |
| Samuel Kaski | University of Aalto | Department of Computer Science, Professor | Approx-Bayes team |
| Takahiro Katagiri | Nagoya University, Information Technology Center | Professor | HPC team |
| Akihiro Ida | The University of Tokyo, Information Technology Center, Project | Associate Professor | HPC team |
| Takeshi Iwashita | Hokkaido University, Information Initiative Center | Professor | HPC team |
| Julien Mairal | Inria Grenoble Rhône-Alpes | Research scientist | Stat-Theory team |
| Eren Mehmet Kiral | RIKEN AIP | Special Postdoctoral Researcher | Math-Science team |
| Kengo Nakajima | The University of Tokyo, Information Technology Center | Professor | HPC team |
| Takeshi Ogita | Tokyo Woman’s Christian University, School of Arts and Sciences | Professor | HPC team |
| Jan Peters | TU Darmstadt | Professor | Approx-Bayes team |
| Judith Rousseau | Université Paris-Dauphine & University of Oxford | Professor | Stat-Theory team |
| Haavard Rue | King Abdullah University of Science and Technology, CEMSE division | Professor | Approx-Bayes team |
| Akiyoshi Sannai | RIKEN AIP | Research Scientist | Math-Science team |
| Mark Schmidt | University of British Columbia, Department of Computer Science | Associate Professor | Approx-Bayes team |
| Arno Solin | University of Aalto, Department of Computer Science | Associate Professor | Approx-Bayes team |
| Siddharth Swaroop | University College London | Assistant Professor | Approx-Bayes team |
| Asuka Takatsu | Tokyo Metropolitan University | Associate Professor | Math-Science team |
| Koichi Tojo | RIKEN AIP | Special Postdoctoral Researcher | Math-Science team |
| Richard Turner | Cambridge University, UK, Department of Engineering | Associate Professor | Approx-Bayes team |
| Mariia Vladimirova | Inria Grenoble Rhône-Alpes | PhD Student | Stat-Theory team |
| Pierre Wolinski | Inria Grenoble Rhône-Alpes & University of Oxford | Post-doctoral fellow | Stat-Theory team |
| Shuji Yamamoto | Keio University/RIKEN AIP | Associate Professor | Math-Science team |
| Wu Lin | University of Central Florida | Assistant Professor | Approx-Bayes team |
Research
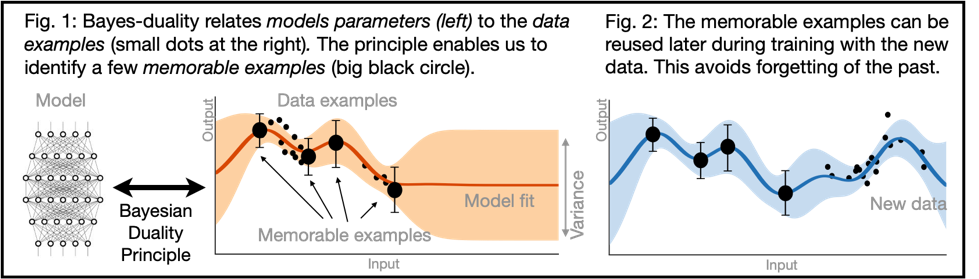
Our goal is to develop a new learning paradigm that enables adaptive, robust, and lifelong learning of AI systems. Deep learning methods are not sufficiently adaptive or robust, e.g., new knowledge cannot be easily added in trained models and, when forced, the old knowledge is easily forgotten. Given a new dataset, the whole model needs to be retrained from scratch on both the old and new data, and training only on the new dataset leads to the catastrophic forgetting of the past. All of the data must be available at the same time, which creates a dependency on large datasets and models that plagues almost all deep learning systems. Our main goal is to fix this by developing a new learning paradigm to support adaptive and robust systems that learn throughout their lives.
We introduce a new learning-principle for machine learning, which we call the Bayes Duality principle or “Bayes-Duality”. The principle exploits the “dual perspectives” of approximate (Bayesian) posteriors, to extend the concepts of duality (similar to convex duality) to nonconvex problems. It is based on a new discovery that natural-gradients used in approximate Bayesian methods automatically give rise to such dual representations. In the past, we have shown that natural-gradients for Bayesian problems yield a majority of machine learning algorithms as special cases (see our paper on the Bayesian Learning Rule). Our goal now is to show that the same approach to apply ideas of duality to nonconvex problems, such as those that arise in deep learning.
Our main goals in the future include the following:
- A theory of Bayes-duality and connections to other dualities
- Theoretical guarantees for adaptive systems based on Bayes-duality
- Practical methods for knowledge transfer and collection in deep learning
Publications
-
Federated ADMM from Bayesian Duality,
(ICLR 2026) [OpenReview] -
Information Geometry of Variational Bayes,
(Information Geometry) M.E. Khan [ ArXiv ]
-
Variational Learning Finds Flatter Solutions at the Edge of Stability,
(NeurIPS 2025) M.E. Khan, [ ArXiv ] Accepted as Spotlight
-
U-ensembles: Improved diversity in the small data regime using unlabeled data,
(AABI 2025)
-
Gaussian Pre-Activations in Neural Networks: Myth or Reality?,
(TMLR 2025) [ ArXiv ]
-
Revisiting concentration results for approximate Bayesian computation,
(Bayesian Analysis 2025) [ HAL ]
-
Compact Memory for Continual Logistic Regression,
(NeurIPS 2025) M.E. Khan -
Variational Learning Induces Adaptive Label Smoothing,
M.E. Khan [ ArXiv ]
-
Natural Variational Annealing for Multimodal Optimization,
M.E. Khan [ ArXiv ]
-
How to Weight Multitask Finetuning? Fast Previews via Bayesian Model-Merging,
M.E. Khan [ ArXiv ]
-
Connecting Federated ADMM to Bayes,
(ICLR 2025) , M.E. Khan, -
Uncertainty-Aware Decoding with Minimum Bayes' Risk,
(ICLR 2025) , , -
Variational Low-Rank Adaptation Using IVON,
(Fine-Tuning in Modern ML (FITML) at NeurIPS 2024) , M.E. Khan, -
Variational Learning is Effective for Large Deep Networks,
(ICML 2024) M.E. Khan,
[ ArXiv ] [ Blog ] [ Code ] Accepted as Spotlight
-
Model Merging by Uncertainty-Based Gradient Matching,
M.E. Khan [ ArXiv ]
-
Improving Continual Learning by Accurate Gradient Reconstructions of the Past,
(TMLR) M.E. Khan [ OpenReview ]
-
The Memory Perturbation Equation: Understanding Model’s Sensitivity to Data,
(NeurIPS 2023) M.E. Khan [ arXiv ]
-
The fine print on tempered posteriors,
(ACML 2023) [ arXiv ] -
Memory-Based Dual Gaussian Processes for Sequential Learning,
(ICML 2023) [ arXiv ] -
Lie-Group Bayesian Learning Rule,
(AISTATS 2023) [ arXiv ]
-
SAM as an Optimal Relaxation of Bayes,
(ICLR 2023) , M.E. Khan [ arXiv ] [ Tweet ]
Accepted for an oral presentation, 5% of accepted papers (75 out of 5000 submissions),
-
The Bayesian Learning Rule,
(JMLR) [ JMLR 2023 ] [ arXiv ] [ Tweet ]
-
Knowledge-Adaptation Priors,
(NeurIPS 2021) [ arXiv ] [ Slides ] [ Tweet ] [ SlidesLive Video ] -
Dual Parameterization of Sparse Variational Gaussian Processes,
(NeurIPS 2021) [ arXiv ] -
Continual Deep Learning by Functional Regularisation of Memorable Past,
(NeurIPS 2020, Oral) [ arXiv ] [ Code ] [ Poster ]
-
Approximate Inference Turns Deep Networks into Gaussian Processes,
(NeurIPS 2019) . [ arXiv ] [ Code ] -
Decoupled Variational Gaussian Inference,
(NIPS 2014) [ Paper and appendix ] -
Fast Dual Variational Inference for Non-Conjugate Latent Gaussian Models,
(ICML 2013) [ Paper ]